Reasoning Graphs: Turn Context to Action
Agents take actions.
How effective those actions are depend on how much agents know about the world they are operating in: Your company, how you do work, the products you sell, the processes you follow.
Most of this information is scattered across multiple systems, and a large portion of it is not stored anywhere at all. This is currently the biggest gap in making agent deployments effective.
We are on the brink of a whole new data architecture tailored for providing context to agents.
The need to store reasoning in memory
Some actions are one-shot: triage this ticket, route this lead, tag this email, etc. You can often get away with shallow context.
Other actions require connecting the dots across multiple sources and across time: taking the right action requires building on inference, step by step.
- How do we answer this RFP without overcommitting?
- How should we scope this proposal?
- Who else should we reach out to for this deal and how?
For these tasks, the agent needs to store the inferences it has made so far, so that it (or another agent) can use them when it is time to take the next reasoning step. These reasoning steps accumulate, and are used at the appropriate time by the agent to take an action or create an artifact.
Actions are built on layers of reasoning that accumulate over time:
- what we heard
- what we learned from it
- what we concluded
- why we concluded it
- and what changed since then
That reasoning needs to live somewhere durable, shareable, and updateable, so it can inform future actions.
Example: Scoping a Proof Of Concept (POC)
Imagine you need a POC proposal for a customer. To be successful, you need to connect everything you've learned so far about the customer, with what you know about the product, and the competition.
Over the past few weeks:
- In a discovery call, the customer shared two real pain points: latency and auditability.
- In a separate thread, someone on your team mentioned that a competitor struggles with parity on a particular feature that your product has.
- Product docs and internal notes clarify what you can credibly deliver in time.
Now, you have to decide: what features should go into the POC scope?
You need a structure to connect the dots. Somewhere to store what you have learned so far about the:
- Customer: the pain points you learned earlier
- Competition: what you learned about the competitor's weaknesses
- Winning features: combines those: "Given this competitor, feature X matters more"
- Solutioning: maps "needs ↔ features"
- POC scope: a scope grounded in the above knowledge
- And finally, POC proposal: a document, including the scope from the previous layer
In other words, the stored reasoning powers future actions, usable across all agents.
Reasoning Graphs are built to store that reasoning.
Without Reasoning Graphs, information is scattered and conclusions are not built up. So when it's time to act, you're doing archaeology, and the dig only gets harder as context grows (and more likely to go wrong).
The Reasoning Graph: data → reasoning → actions
Here's a simple way to think about Reasoning Graphs:
1) Raw data layer
A Reasoning Graph connects directly to sources of raw data: Emails, call records, web research, product docs, customer data, Slack threads. This is used to build the memory.
2) Reasoning layer
The Reasoning layer turns unstructured data like emails, calls, docs into usable conclusions generated through multi-step inference. And keeps updating them as new evidence arrives.
Think of it as a living graph that updates bottom-up:
New data comes in →
Conclusions and their sources update →
Higher-level understanding updates → Actions created 🚀
The graph doesn't store raw data, but inferences based on that data, and the structure of how those relate, so reasoning can compound over time.
Updating, unlearning and de-duplicating: Sometimes during updates, new information may contradict with what is already stored in the graph. When that happens, the agent chooses what source to trust, and updates the conclusion with an explanation, effectively unlearning the incorrect inference, sometimes it takes the form of deduplicating [1]. This is a difficult technical problem with nuances that we will dig into in a future post.
That ability to learn and unlearn is what makes Reasoning Graphs reliable.
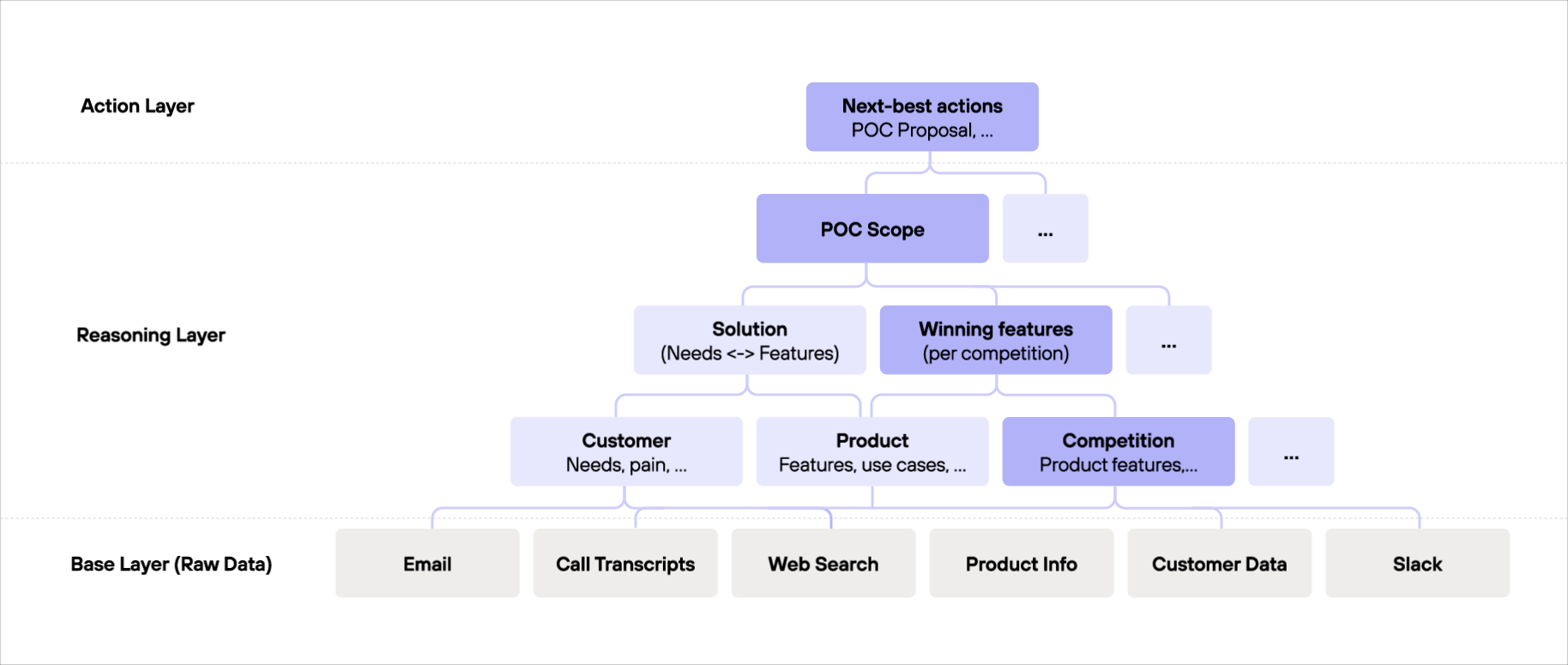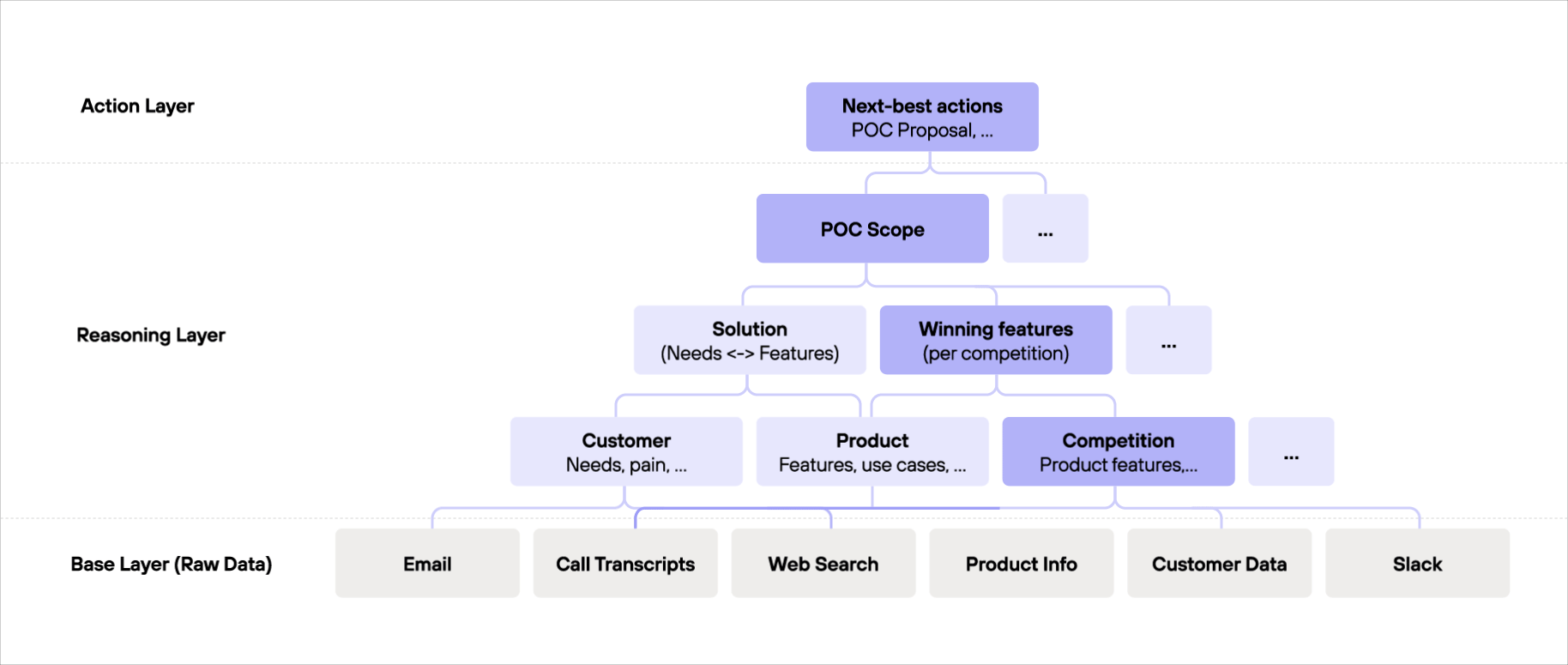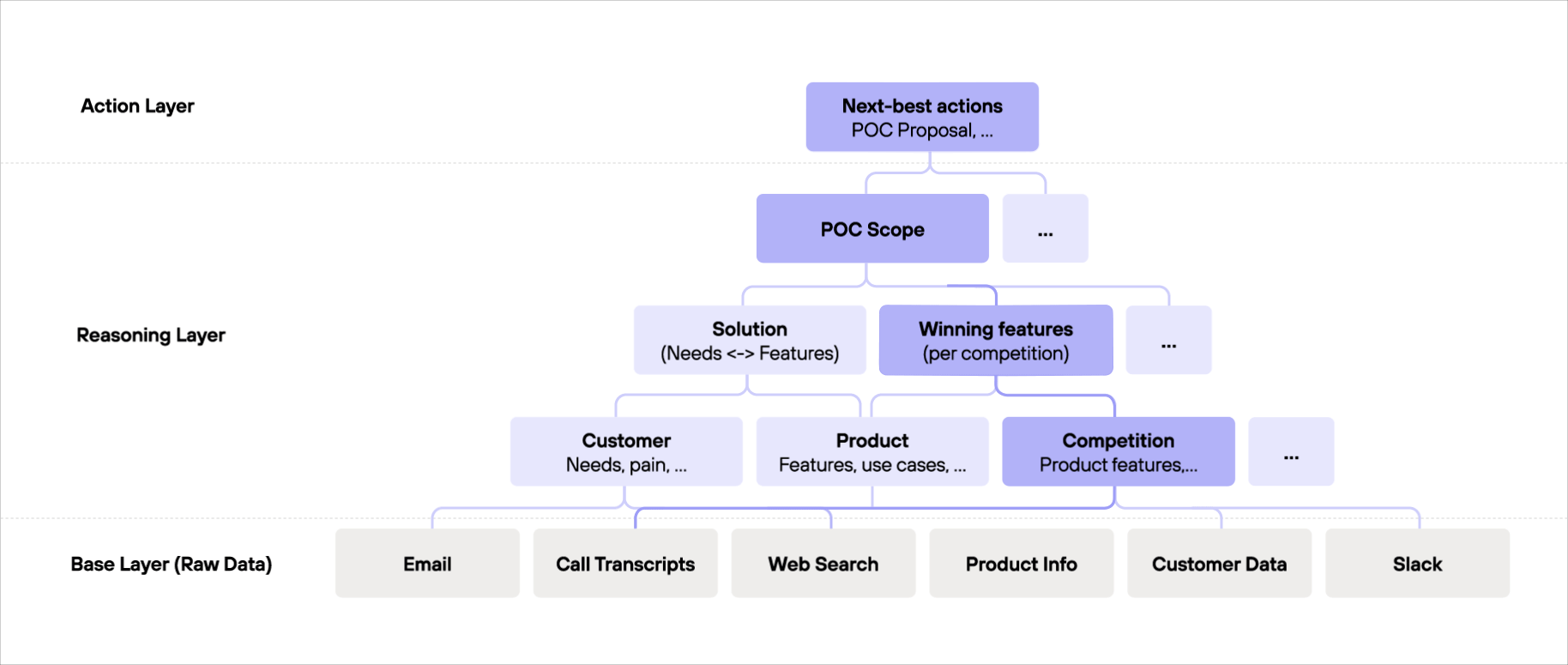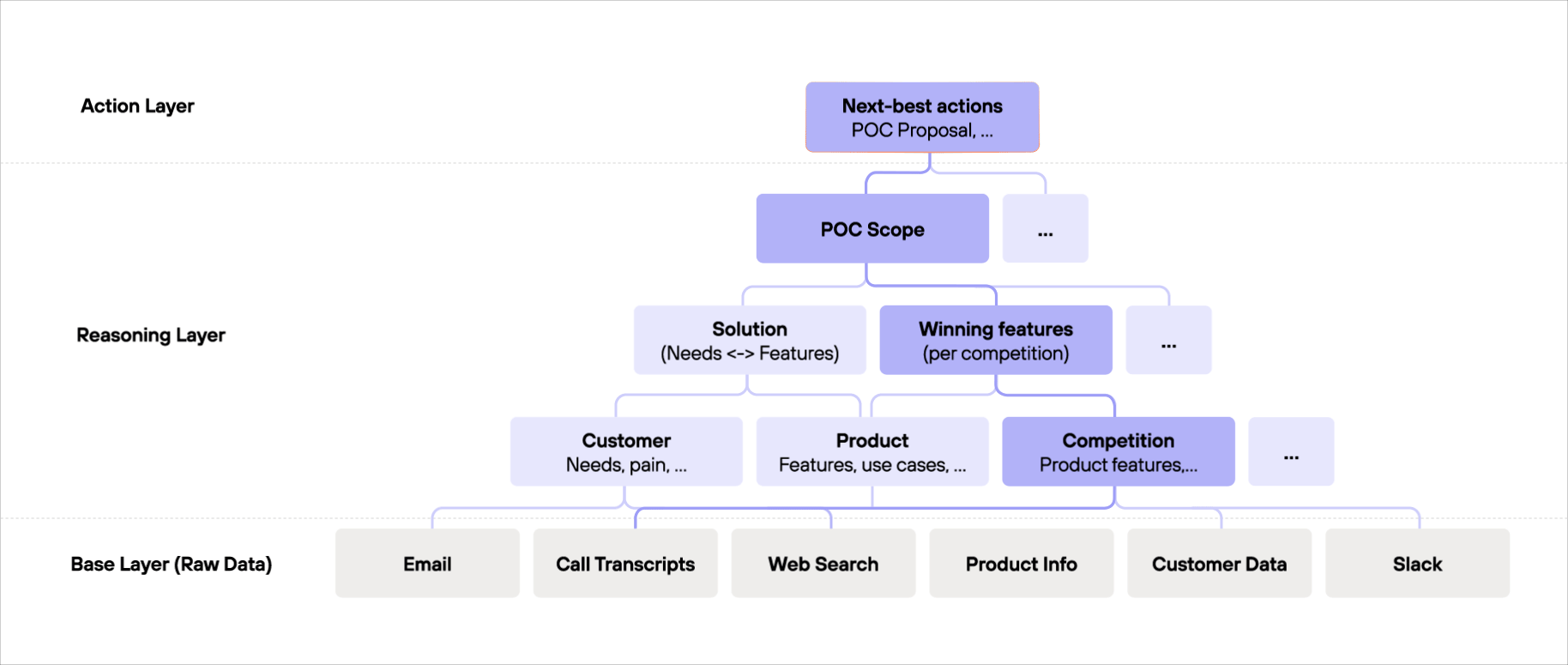
Reasoning Graphs can be configured for different use cases to store agent reasoning and enable multi-agent collaboration. This example visualizes what a configuration for a sales use case can look like.
3) Action layer: what to do next
A Reasoning Graph supports an agent taking action based on what has been learned so far. The final layers of a Reasoning Graph are often actions or artifacts: "next best actions," proposals, POCs, follow-ups, etc.
As new raw data comes in, the Reasoning Graph is updated in a bottom-up cascading manner: data is ingested, is reasoned over layer by layer, and actions pop up from the top.
This is the shift: evolution from a knowledge base to an operational engine.
The enterprise reality: access-controlled reasoning
One important caveat: A memory for enterprise needs to consider who is allowed to know what.
Raw sources have permissions. But reasoning is most valuable when it is compound: it's synthesized from multiple sources across time.
So there is a question to address:
If a conclusion is derived from mixed-permission data, how can we determine who can see the conclusion? How do we prevent agents from leaking restricted content through reasoning?
This is the first of a series on enterprise-grade agentic memory. We'll cover:
- Agent memory (learning, unlearning, and memory updates)
- Reliability (accuracy, explainability)
- Context engineering more broadly and connections to Context Graphs, File Systems, RAG.
- Security and ACLs (permissions and data lineage)
- Human oversight (how humans steer the system)
- How Reasoning Graphs scale (data partitioning, pruning, archiving)
- Configurability (to adapt to different enterprises and business processes)
If you've tried shipping agentic memory: where did it break first?
[1] Agent actions may overlap or some reasoning nodes may need to get merged. One example is people's names: our CEO's name, Nilou, shows up in transcripts as "Nilo," "Neo," "Nu," etc. Within the Person collection of the reasoning graph, the agent merges these into a single person record, with an explanation for why.
